Errors
Table of contents
analyze_false_positive_errors_for_category()
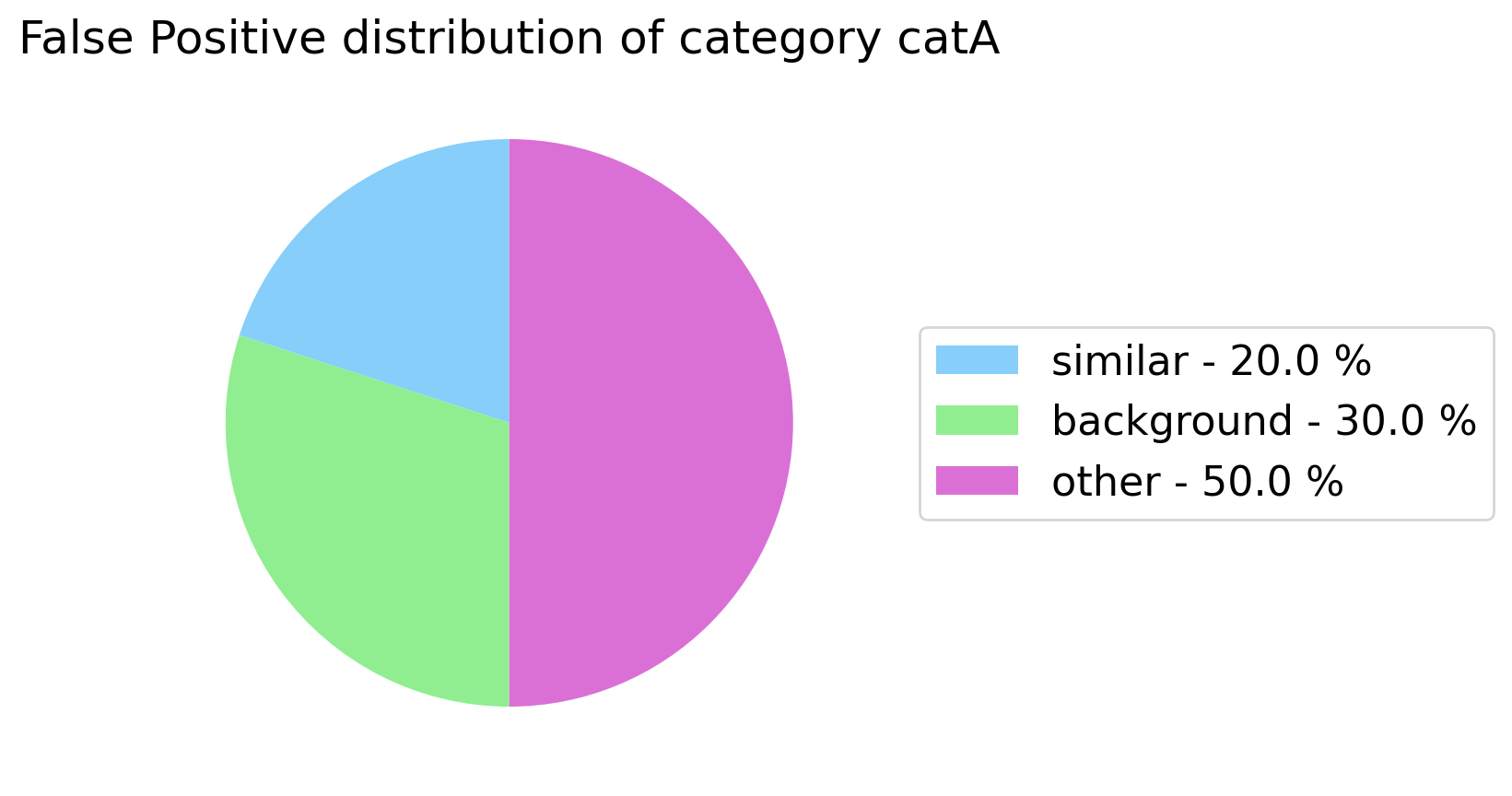
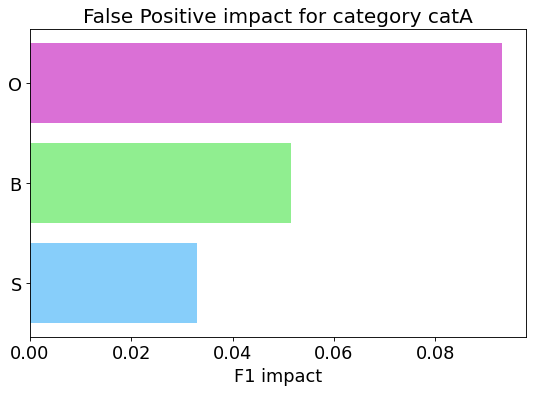
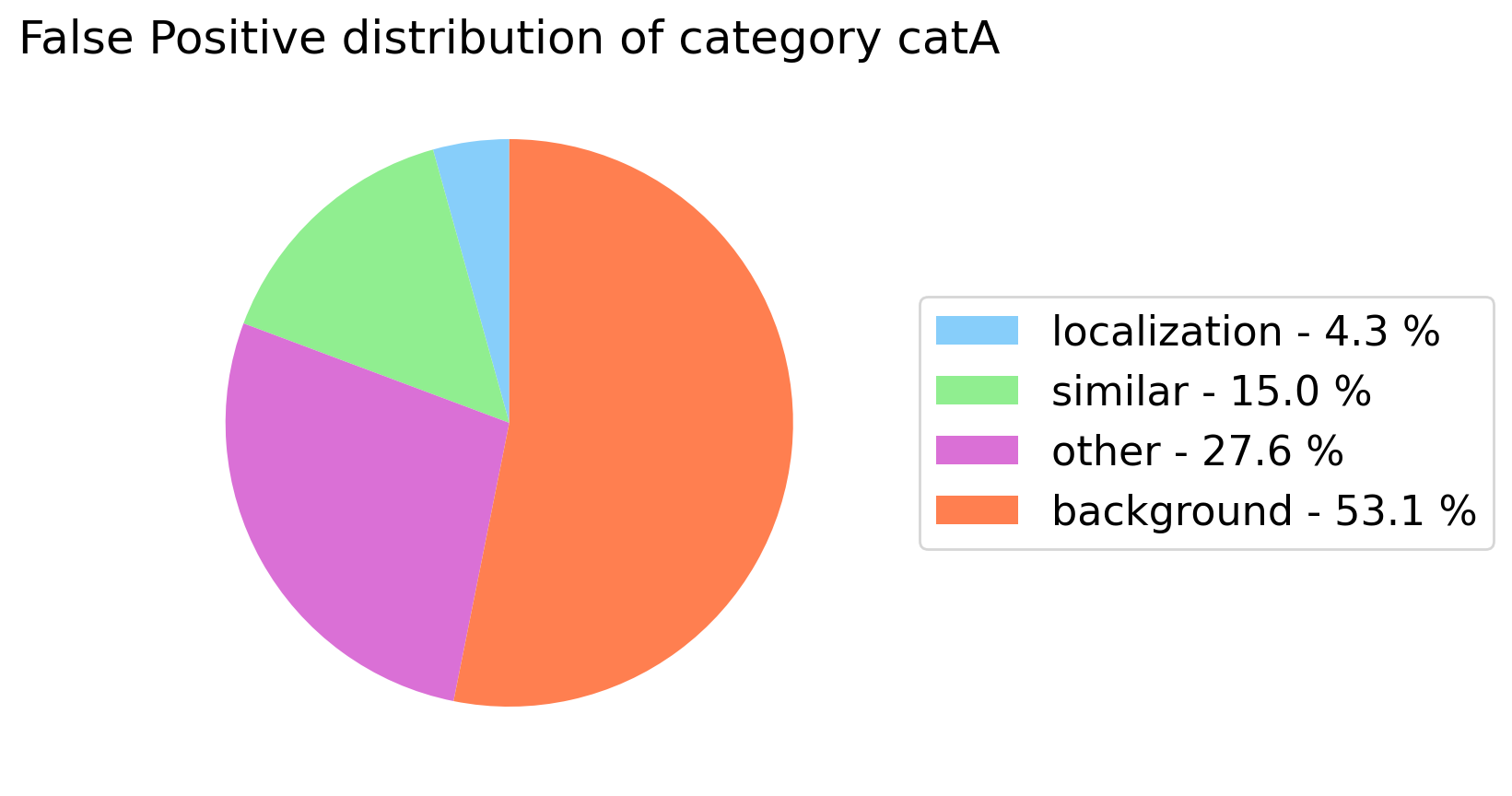
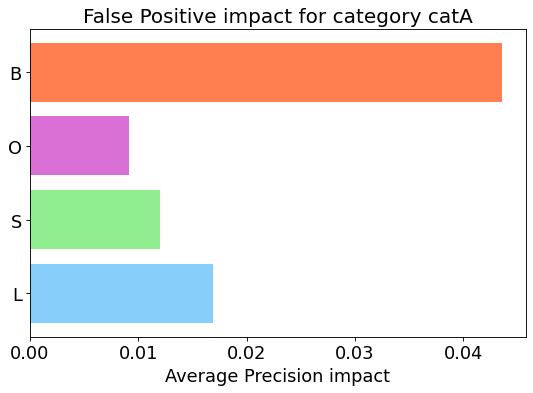
It analyzes the false positives for a specific category, by identifying the type of the errors and shows the gain that the model could achieve by removing all the false positives of each type.
For classification tasks we have categorized the False Positive into three different types:
- Background: the observation does not represent any of the categories (only for multi-label classification task).
- Similar: the observation represents a similar category to the predicted one.
- Other: all the other cases.
For localization tasks we have identified four different errors:
- Background: the category predicted has been confused with the background or the IoU with the corresponding annotation is less than a minimum threshold (set to 0.2).
- Localization: the model has correctly predicted the category but the IoU with the corresponding annotation is less than the threshold.
- Similar: the ground truth annotation represents a similar category to the predicted one and the IoU is equal or greater than the threshold.
- Other: all the other cases.
Parameters
- category
str- Name of the category to be analyzed.
- metric
Metrics, optional- Evaluation metric used for the analysis. If not specified, the default one is used.
(default is None) - show
bool, optional- Indicates whether the plot should be shown or not. If False, returns the results as dict.
(default is True)
Example
Classification
from odin.classes import AnalyzerClassification
my_analyzer = AnalyzerClassification("my_classifier_name", my_classification_dataset)
my_analyzer.analyze_false_positive_errors_for_category('catA')
Localization
from odin.classes import AnalyzerLocalization
my_analyzer = AnalyzerLocalization("my_detector_name", my_localization_dataset)
my_analyzer.analyze_false_positive_errors_for_category('catA')
Tasks supported
| Binary Classification | Single-label Classification | Multi-label Classification | Object Detection | Instance Segmentation |
|---|---|---|---|---|
| no | yes | yes | yes | yes |
analyze_false_positive_errors()
For each class, it analyzes the false positives by identifying the type of the errors and shows the gain that the model could achieve by removing all the false positives of each type.
Parameters
- categories
list, optional- List of categories to be included in the analysis. If not specified, all the categories are included.
(default is None) - metric
Metrics, optional- Evaluation metric used for the analysis. If not specified, the default one is used.
(default is None) - show
bool, optional- Indicates whether the plot should be shown or not. If False, returns the results as dict.
(default is True)
Example
Classification
from odin.classes import AnalyzerClassification
my_analyzer = AnalyzerClassification("my_classifier_name", my_classification_dataset)
my_analyzer.analyze_false_positive_errors()
N.B. As example, it is shown only the output of a single category, but the analysis is performed for all the categories selected.
Localization
from odin.classes import AnalyzerLocalization
my_analyzer = AnalyzerLocalization("my_detector_name", my_localization_dataset)
my_analyzer.analyze_false_positive_errors()
N.B. As example, it is shown only the output of a single category, but the analysis is performed for all the categories selected.
Models comparison
Example
Classification
from odin.classes import ComparatorClassification
similar_categories = [[1, 3], [2, 3]]
my_comparator = ComparatorClassification(dataset_gt_param, classification_type, models_proposals, similar_classes=similar_categories)
my_comparator.analyze_false_positive_errors()
Localization
from odin.classes import ComparatorLocalization
my_comparator = ComparatorLocalization(dataset_gt_param, task_type, models_proposals, similar_classes=similar_categories)
my_comparator.analyze_false_positive_errors()
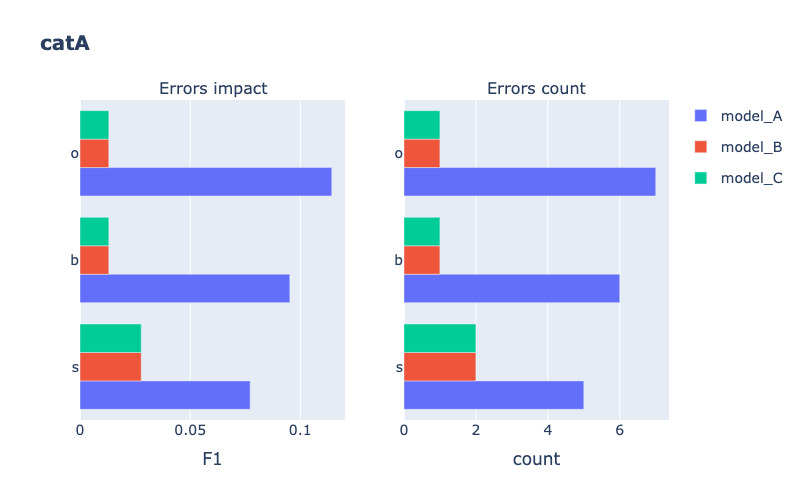
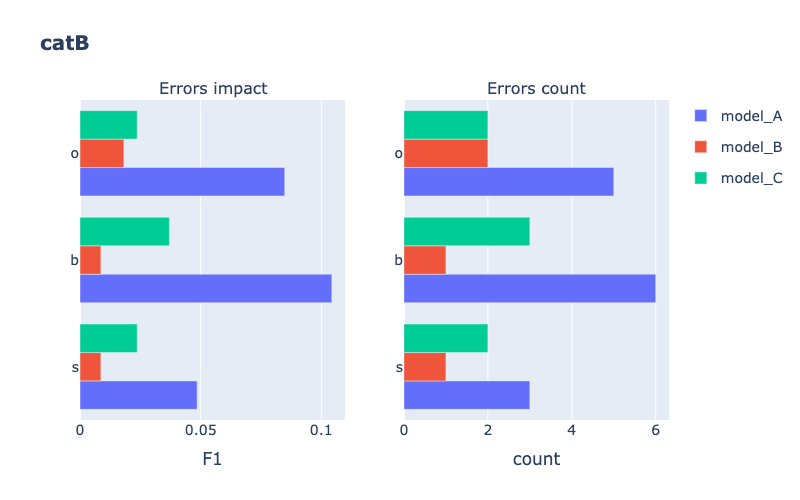
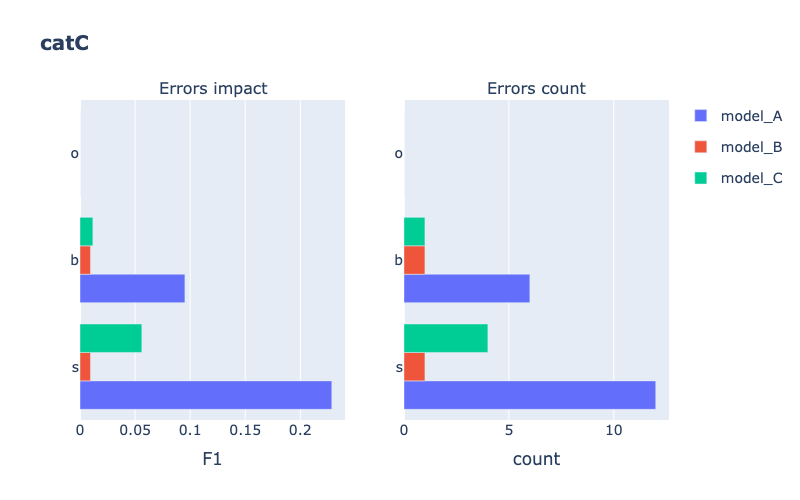
Tasks supported
| Binary Classification | Single-label Classification | Multi-label Classification | Object Detection | Instance Segmentation |
|---|---|---|---|---|
| no | yes | yes | yes | yes |
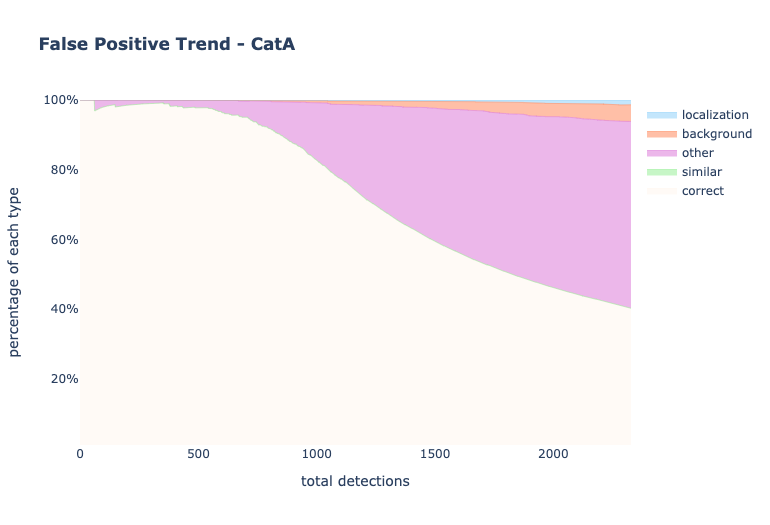
analyze_false_positive_trend_for_category()
It analyzes the trend of the false positives by indicating the percentage of each error type.
Parameters
- category
str- Name of the category to be analyzed.
- include_correct_predictions
bool, optional- Indicates whether the correct detections should be included in the trend analysis or not.
(default is True) - show
bool, optional- Indicates whether the plot should be shown or not. If False, returns the results as dict.
(default is True)
Example
Classification
from odin.classes import AnalyzerClassification
my_analyzer = AnalyzerClassification("my_classifier_name", my_classification_dataset)
my_analyzer.analyze_false_positive_trend_for_category('catA')
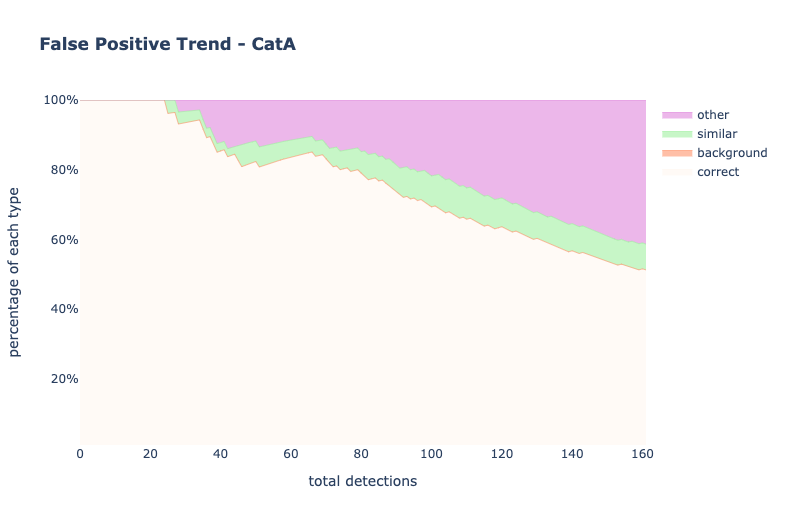
Localization
from odin.classes import AnalyzerLocalization
my_analyzer = AnalyzerLocalization("my_detector_name", my_localization_dataset)
my_analyzer.analyze_false_positive_trend_for_category('catA')
Tasks supported
| Binary Classification | Single-label Classification | Multi-label Classification | Object Detection | Instance Segmentation |
|---|---|---|---|---|
| no | yes | yes | yes | yes |
analyze_false_positive_trend()
For each class, it analyzes the trend of the false positives by indicating the percentage of each error type.
Parameters
- categories
list, optional- List of categories to be included in the analysis. If not specified, all the categories are included.
(default is None) - include_correct_predictions
bool, optional- Indicates whether the correct detections should be included in the trend analysis or not.
(default is True) - show
bool, optional- Indicates whether the plot should be shown or not. If False, returns the results as dict.
(default is True)
Example
Classification
from odin.classes import AnalyzerClassification
my_analyzer = AnalyzerClassification("my_classifier_name", my_classification_dataset)
my_analyzer.analyze_false_positive_trend()
N.B. As example, it is shown only the output of a single category, but the analysis is performed for all the categories selected.
Localization
from odin.classes import AnalyzerLocalization
my_analyzer = AnalyzerLocalization("my_detector_name", my_localization_dataset)
my_analyzer.analyze_false_positive_trend()
N.B. As example, it is shown only the output of a single category, but the analysis is performed for all the categories selected.
Tasks supported
| Binary Classification | Single-label Classification | Multi-label Classification | Object Detection | Instance Segmentation |
|---|---|---|---|---|
| no | yes | yes | yes | yes |
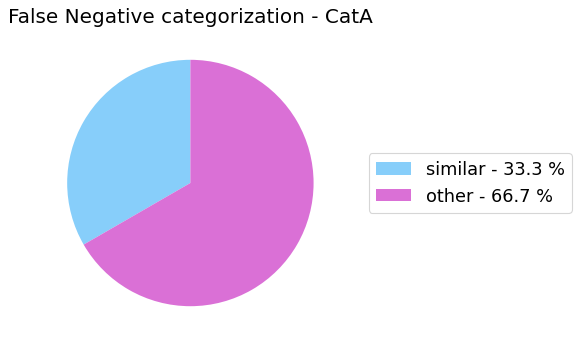
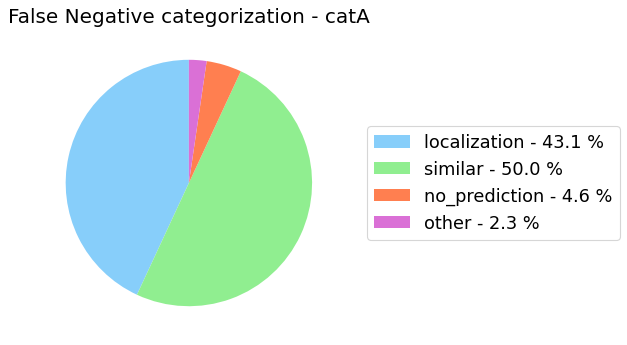
analyze_false_negative_errors_for_category()
It analyzes the false negatives for a specific category, by identifying the type of the errors.
For classification tasks we have categorized the false negative into two different types:
- Similar: the model has wrongly predicted a class which is similar to the one represented in the observation.
- Other: all the other cases.
For localization tasks we have identified four different errors:
- Localization: the model has correctly predicted the category but the IoU with the corresponding annotation is less than the threshold but equal or greater than a minimum threshold (set to 0.2).
- Similar: the ground truth annotation represents a similar category to the predicted one and the IoU is equal or greater than the threshold.
- No_prediction: the ground truth annotation does not have a corresponding prediction or the IoU is less than a minimum threshold (set to 0.2).
- Other: all the other cases.
Parameters
- category
str- Name of the category to be analyzed.
- show
bool, optional- Indicates whether the plot should be shown or not. If False, returns the results as dict.
(default is True)
Example
Classification
from odin.classes import AnalyzerClassification
my_analyzer = AnalyzerClassification("my_classifier_name", my_classification_dataset)
my_analyzer.analyze_false_negative_errors_for_category('catA')
Localization
from odin.classes import AnalyzerLocalization
my_analyzer = AnalyzerLocalization("my_detector_name", my_localization_dataset)
my_analyzer.analyze_false_negative_errors_for_category('catA')
Tasks supported
| Binary Classification | Single-label Classification | Multi-label Classification | Object Detection | Instance Segmentation |
|---|---|---|---|---|
| no | yes | yes | yes | yes |
analyze_false_negative_errors()
For each class, it analyzes the false negatives by identifying the type of the errors.
Parameters
- categories
list, optional- List of categories to be included in the analysis. If not specified, all the categories are included.
(default is None) - show
bool, optional- Indicates whether the plot should be shown or not. If False, returns the results as dict.
(default is True)
Example
Classification
from odin.classes import AnalyzerClassification
my_analyzer = AnalyzerClassification("my_classifier_name", my_classification_dataset)
my_analyzer.analyze_false_negative_errors()
N.B. As example, it is shown only the output of a single category, but the analysis is performed for all the categories selected.
Localization
from odin.classes import AnalyzerLocalization
my_analyzer = AnalyzerLocalization("my_detector_name", my_localization_dataset)
my_analyzer.analyze_false_negative_errors()
N.B. As example, it is shown only the output of a single category, but the analysis is performed for all the categories selected.
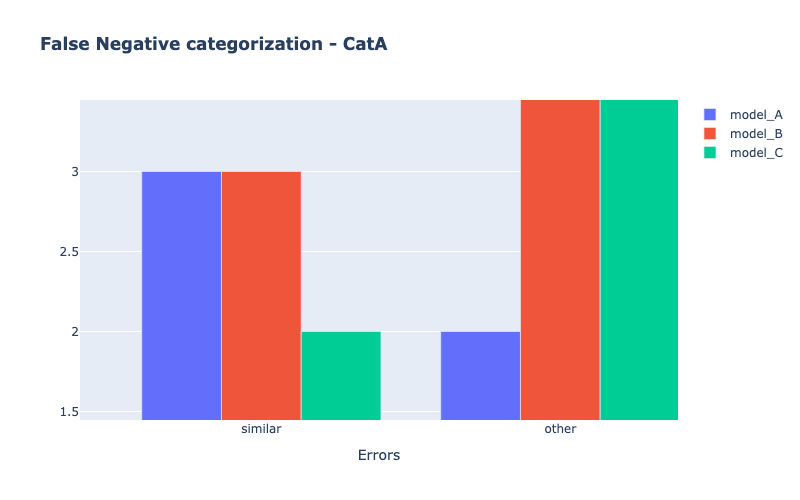
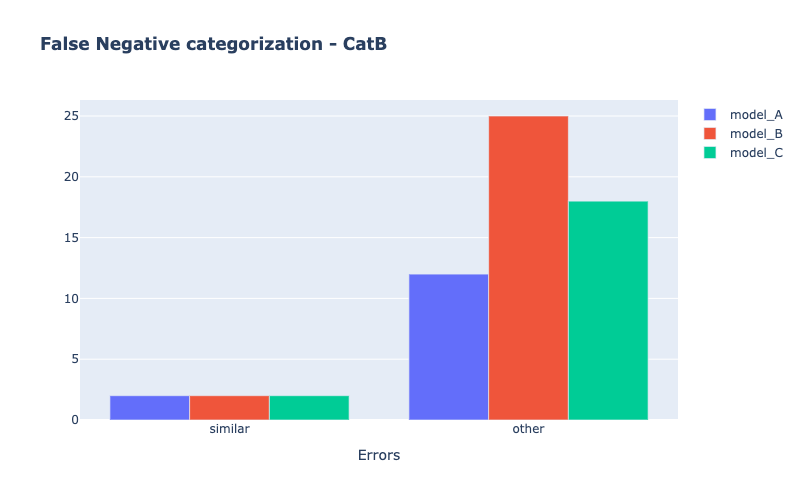
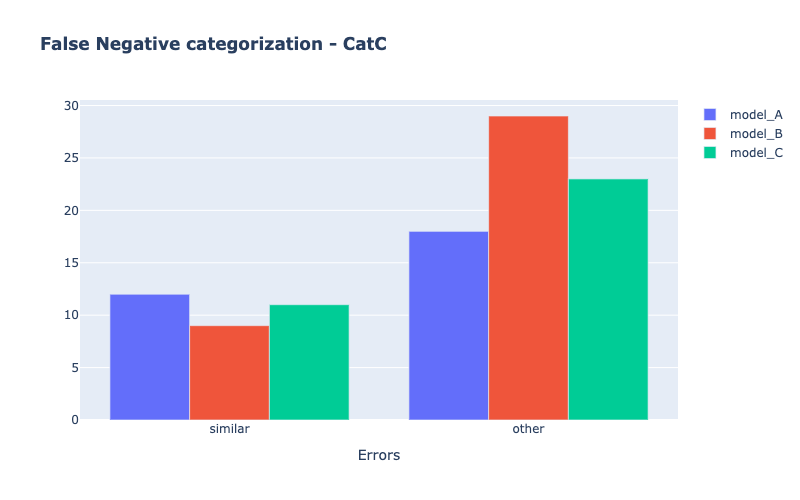
Models comparison
Example
Classification
from odin.classes import ComparatorClassification
similar_categories = [[1, 3], [2, 3]]
my_comparator = ComparatorClassification(dataset_gt_param, classification_type, models_proposals, similar_classes=similar_categories)
my_comparator.analyze_false_negative_errors()
Localization
from odin.classes import ComparatorLocalization
my_comparator = ComparatorLocalization(dataset_gt_param, task_type, models_proposals, similar_classes=similar_categories)
my_comparator.analyze_false_negative_errors()
Tasks supported
| Binary Classification | Single-label Classification | Multi-label Classification | Object Detection | Instance Segmentation |
|---|---|---|---|---|
| no | yes | yes | yes | yes |